

Pidän tiedostoista. En kaikista, mutta noin yleensä. PDF-tiedostoista en pidä. Word doc(x)-tiedostomuotoon on kehittynyt eräänlainen viha-rakkaussuhde, vähän niin kuin Helsingin Sanomiin: välillä se saa raivon partaalle, mutta ilman sitä ei voi oikein elääkään. Excel-tiedostot ovat kiinnostavia ja haluaisin ymmärtää niitä paremmin. PowerPoint-tiedostoihin suhtaudun nykyään yhdentekevästi (ennen olin niistäkin kiinnostunut). Maailma tulisi toimeen hyvin ilman niitä.
Eniten pidän tekstitiedostoista. Ensinnäkin, niitä on niin paljon erilaisia ja ne jaksaa aina yllättää, mutta harvoin ne ärsyttävät. Ja jos tekstitiedoston sisällön on kirjoittanut joku inhimillinen olento, se sisältö on yleensä täyttä asiaa, sitä ei ole liikaa, ja on tarkoitus, että se ihan oikeasti luetaan kokonaan. Eivätkä tekstitiedostot vaadi isoja ja monimutkaisia ohjelmia, jotta niitä voisi tutkia.
Usein kyllä tekstitiedostot ovat jonkun automatiikan tai prosessin tuottamia, kuten seuraava esimerkkini. Se on tietokanta-dumppi erään tahon sisällöstä, joka on tarkoitettu ihmisen luettavaksi. Ja meille se tuli käännettäväksi. Ja minun piti selvittää, miten sen saisi sellaiseen muotoon, että sen voisi viedä käännöstyökaluun, niin että joku voisi sen kääntää. Tämä on lyhyt tarina tuon tiedoston valmistelusta kääntöön.
Jos tekstitiedoston sisällön on kirjoittanut joku inhimillinen olento, se sisältö on yleensä täyttä asiaa, ja on tarkoitus, että se ihan oikeasti luetaan kokonaan.
Ensimmäinen vaihe on tutkia tiedoston sisältöä ja tarkistaa, löytyykö tiedostomuodolle jo valmista "filtteriä" (tai "parseria", termit vaihtelee sen mukaan, mistä työkalusta on kyse), eli säännöstöä, jonka avulla teksti segmentoidaan ja tuodaan näkyviin käännöstyökalun editoriin käännettävät osiot ja jätetään piiloon ulkoinen sisältö, jota ei ole tarkoitus kääntää.
Officen tiedostoillehan on olemassa valmiit säännöstöt (ja aika monelle muullekin), mutta jos kyse on tekstitiedostosta, asia on vähän mutkikkaampi. Tässä esimerkissä on kyse .json tiedostosta.
Avaan tiedoston EmEditorilla, ja sen sisältö näyttää seuraavalta:
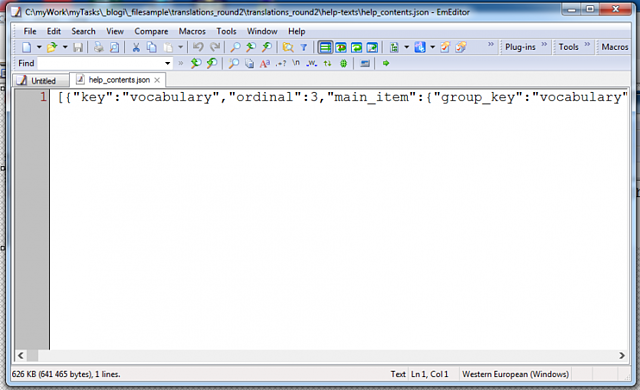
Teksti näytäisi olevan yhdellä rivillä, vaikka se on aika iso, yli 600 kt. Käännöstyökalu kyllä tunnistaa tiedostomuodon, mutta tekstin kääntäminen ei onnistu suoraan.
Kokeilen vielä oikeaa lokalisointityökalua, joka näyttäisi tunnistavan tiedostomuodon:
Katsotaan, saadaanko sisältöä näkyviin, luodaan ensin ns. tekstilista (nämä on nyt näitä lokalisointityökalun käsitteitä vaan…)
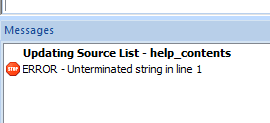
Hmm…. yritetään kuitenkin vielä avata tiedosto editointitilaan:
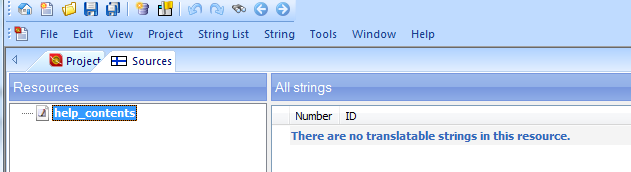
Ei siis onnistu lokalisointityökalullakaan suoraan, eli seuraavaksi pitää määrittää tekstin rakenne ja ne elementit, jotka edeltää käännettävää tekstiä ja joihin käännettävän tekstin osuus päättyy. Näiden tietojen avulla sitten yritän luoda säännöstön, jonka avulla tiedosto voidaan viedä käännöstyökaluun käännettäväksi.
Palataan siis takaisin EmEditoriin ja tarkastellaan sisältöä tarkemmin. Otetaan ensin rivitys päälle.
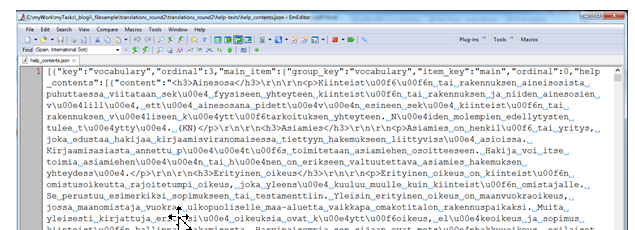
Nyt näkyy jo ihmisen ymmärtämää tekstiä (tosin lukemista vähän häiritsee ns. escaped unicode merkit \u00e4 jne), ja kielikin on oikea, tämä pitää kääntää suomesta ruotsiin. Rakennetta tästä ei tosin vielä pysty selvittämään, eli tiedostolle pitää vielä tehdä ns. pretty print (jos tiedät, mitä tämä on suomeksi, kerro minullekin) ja otetaan samalla rivitys pois päältä:
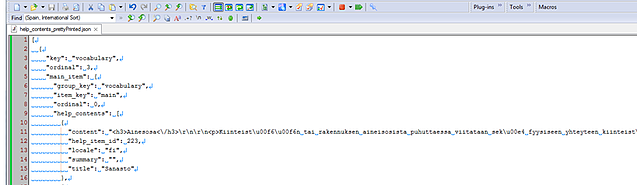
A vot, tämän kanssa voi jo elää! Pystyn tästä rakenteesta määrittämään, mistä teksti alkaa ja mihin loppuu, ja tekemään tarvittavat säädöt käännöstyökalun säännöstöön.
Tässä menisi aika pitkään, jos kävisin kaikki yksityiskohdat läpi, joita tämän tiedostomuodon kanssa tulee eteen, mutta noin lyhyesti, seuraavat vaiheet pitää vielä käydä läpi, ennen kuin tiedoston voi viedä käännöstyökaluun:
- escaped-merkkien muunto normaaleiksi (esim. \u00e4 -> ä)
- sisällön tallennus UTF-8-muotoon (BOMin kanssa) Jos BOM ei avaudu, siitä käytetään myös englannin nimitystä Signature, mutta jos sekään ei avaudu, kurkkaa vaikka sivua
- uuden tekstifiltterin (säännöstön) määritys käännöstyökalussa
- tekstiin upotettujen tägien määritys joko sisäiseksi tai ulkoiseksi (esim. ulkoinen tägipari, sisäinen, ja siellä oli mm. seuraavanlaisia sisäisiä muuttujia, joiden välissä on käännettävää tekstiä: ${link:Ks. määräosan luovutus kaupalla|real_estate_portion_transfer})
Kun nuo kaikki toimet on tehty, olen valmis viemään tiedoston käännöstyökaluun ja tarkistamaan, että kaikki toimii, ja että se, mikä pitää kääntää, tulee käännettyä. Teksti näyttää ihan hyvältä käännöstyökalun editorissa, sisäiset tägit näkyvät oikein:


Tarkistan vielä, että kaikki tosiaan tulee käännetyksi pseudokääntämällä tekstin ja vertailemalla alkuperäiseen tiedostoon. Kun olen riittävän tyytyväinen tulokseen, lähetän työn eteenpäin.
Kaiken kaikkiaan sain kulumaan tähän alkuvalmisteluun pari päivää (json-tiedosto ei ollut ainoa tiedostomuoto, joka sisältyi samaan työtilaukseen) ja siltikin taisi käydä niin, että kaikki ei mennyt ihan putkeen, eli lopputoimissa tuli muutama yllätys vastaan, mutta ei siitä sen enempää.
Ai niin, miten paljon tässä sisällössä oli sitten käännettävää? Sitä oli reilut 23 000 sanaa ja kaikki siis alun perin yhdellä tekstirivillä!