

Jag gillar filer. Kanske inte riktigt alla, men jag kan nog säga att jag gillar de flesta typerna. Några jag däremot inte gillar är PDF-filer. Microsoft Words doc- och docx-format har jag utvecklat en sorts hatkärlek till – lite som till min dagstidning: ibland blir jag galen på den, men jag klarar mig ändå inte riktigt utan den. Excelfiler är intressanta och jag skulle vilja förstå dem bättre. Numera är jag dock rätt likgiltig till PowerPointfiler (men förr var jag intresserad av dem också). Nu kan jag nog tycka att världen skulle klara sig rätt bra utan dem.
Textfiler är mina absoluta favoriter. För det första finns de i olika format, och de bara fortsätter att överraska mig och irriterar mig bara i undantagsfall. Det viktigaste är att om en textfil har skrivits av en människa är innehållet oftast relevant, lagom långt och tänkt att läsas i sin helhet. Dessutom krävs det oftast ingen komplicerad programvara för att kunna öppna och läsa dem.
Däremot är det sant att textfiler ofta har skapats automatiskt eller har blivit till som ett resultat av någon typ av process, som i följande exempel. Det är en databasexport av en kunds material, men det är avsett att läsas av människor. Och det kom till oss för att översättas. Jag blev tvungen att komma på hur jag skulle konvertera filen till ett format som kunde importeras till vårt översättningsverktyg och sedan översättas. Här följer en beskrivning i korta drag av hur jag förberedde filen för översättning.
Det viktigaste är att om en textfil har skrivits av en människa är innehållet oftast relevant, lagom långt och tänkt att läsas i sin helhet.
Det första steget var att kontrollera filens innehåll och se om det fanns ett filter eller en parser för filformatet. Filter och parsrar (man använder olika termer i olika verktyg) är en samling regler som används för att dela upp texten i mindre segment så att man kan visa den översättningsbara texten i ett översättningsverktyg och dölja allt som inte ska översättas.
Dessa regelsamlingar finns för Officefiler (och många andra filformat), men när det handlar om textfiler blir det lite mer komplicerat. Filen i det här exemplet var en .json-fil:
När jag öppnade filen i EmEditor såg innehållet ut så här:
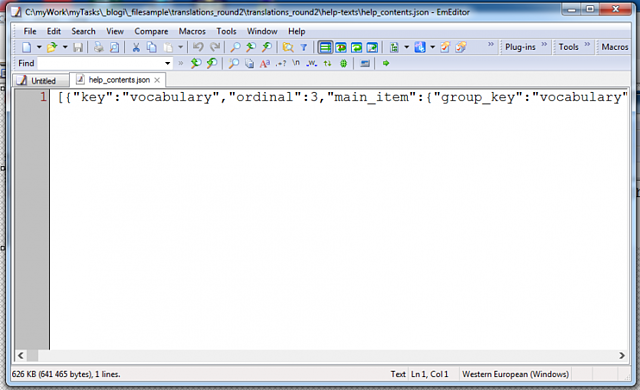
Hela texten låg på en och samma rad, och filen var ganska stor, mer än 600 kB. Jag bestämde mig för att testa om översättningsverktyget kände igen filformatet, så jag importerade filen direkt i vårt vanliga översättningsverktyg.
Sedan provade jag ett specialiserat lokaliseringsverktyg, och då verkade det gå lite bättre:
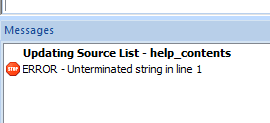
Nästa fråga var om det faktiskt skulle visas någon text. Först skapade jag en textlista (som är den term som används i verktyget).
Och sedan försökte jag öppna filen för redigering:
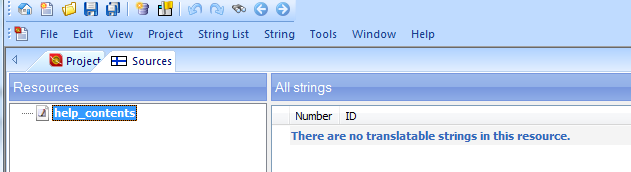
Det var tydligt att filen inte gick att öppna ens med lokaliseringsverktyget, vilket betydde att jag måste specificera textstrukturen och ange vilka element som kom före och efter de översättningsbara textsegmenten. Med hjälp av den här informationen försökte jag sedan skapa en uppsättning regler som skulle göra att det gick att importera filen till översättningsverktyget.
Jag återvände till EmEditor för att ta en ny titt på innehållet. Först aktiverade jag radbrytning.
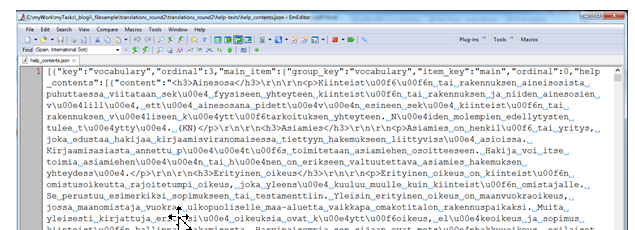
Detta gjorde texten läsbar (även om de undantagskodade Unicodetecknen, som ”\u00e4”, gjorde läsningen lite besvärlig), och även språket tolkades rätt – det här var en text som skulle översättas från finska till svenska. Det gick fortfarande inte att komma underfund med textens struktur, vilket är anledningen till att jag blev tvungen att dela upp innehållet i dess syntaktiska beståndsdelar och inaktivera radbrytningen:
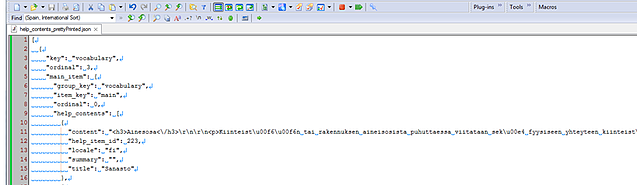
Nu började det likna något! Med hjälp av den här strukturen kunde jag definiera var texten började och slutade och göra en del nödvändiga justeringar i regeluppsättningen för översättningsverktyget.
Att gå igenom alla detaljer i arbetet med det här filformatet skulle ta för lång tid, men i korthet måste man utföra följande åtgärder innan filen kan importeras i översättningsverktyget:
- konvertera undantagstecken till vanliga tecken (t.ex. \u00e4 -> ä)
- spara innehållet i UTF-8-format (med BOM). Om termen BOM inte säger dig något – det kallas även signatur, men om inte heller det säger dig något – kan du läsa mer här
- ange ett nytt textfilter (en regeluppsättning) i översättningsverktyget
- ange om taggarna som är inbäddade i texten ska vara interna eller externa (t.ex. , som är ett externt taggpar, eller , som är ett internt taggpar. Texten innehöll även följande interna parametrar med översättningsbar text mellan dem: ${link:Ks. määräosan luovutus kaupalla|real_estate_portion_transfer})
När alla åtgärderna ovan är klara är jag redo att importera texten till översättningsverktyget, att kontrollera att allt fungerar som det ska och att se till att all översättningsbar text faktiskt kommer med och blir översatt. Texten ser bra ut i översättningsverktyget och de interna taggarna visas som de ska:


Till slut kontrollerar jag att allt kommer att översättas genom att göra en pseudoöversättning av texten och jämföra översättningen med originalfilen. När jag är nöjd med resultatet skickar jag iväg filerna för översättning.
Allt som allt har jag tillbringat ett par dagar med det här förberedelsearbetet (json-filen var inte det enda filformatet som ingick i den här beställningen), och om jag minns rätt stötte vi på ytterligare några problem under avslutningsfasen. Men det är en annan historia.
Just det! Hur många översättningsbara ord innehöll filen då? Över 23 000 faktiskt och från början låg alla på samma rad!